What comes to mind when you hear the term “Machine Learning”? A bunch of programmers hunched over their computers in a dark room, working on something completely virtual & divorced from reality? A group of scientists creating a Frankenstein monster that has no resemblance to us whatsoever?
It may certainly seem that way, but you’d be wrong. The accomplishments of Machine Learning (Self-driving cars, human handwriting parsing, IBM Watson) are certainly very technological in nature. But in truth, Machine Learning is equal parts Art and Philosophy, incorporating deep Epistemological insights in order to better make sense of the world. Machine Learning is in essence, a simplified & structured version of what goes on in our minds every single day, in our quest for knowledge.
If this “quest for knowledge” sounds like a bunch of mumbo jumbo and you’re wondering how it’s actually relevant to us, consider the following: We were all born without any knowledge whatsoever of how the world works. Since then, every single day, every single thing we observe around us, is a data point that we accumulate. And by interpreting these data points, we are able to gain knowledge about the underlying mechanisms that lead to these data points, and more abstractly, “how the world works.”
Life is a massive swarm of data points, and consciously or subconsciously, we are engaged, every single day, in an epistemological quest for knowledge. And one of the most central challenges, in this quest for knowledge, is knowing how to correctly interpret all this data. And that is exactly where Machine Learning comes in.
Overfitting: Keep it Simple
If this all seems overly abstract, let’s consider a concrete example. Imagine that you’re a biologist running a bunch of experiments on the relationship between temperature & enzyme activity. You collect a variety of data points, that looks like the following:
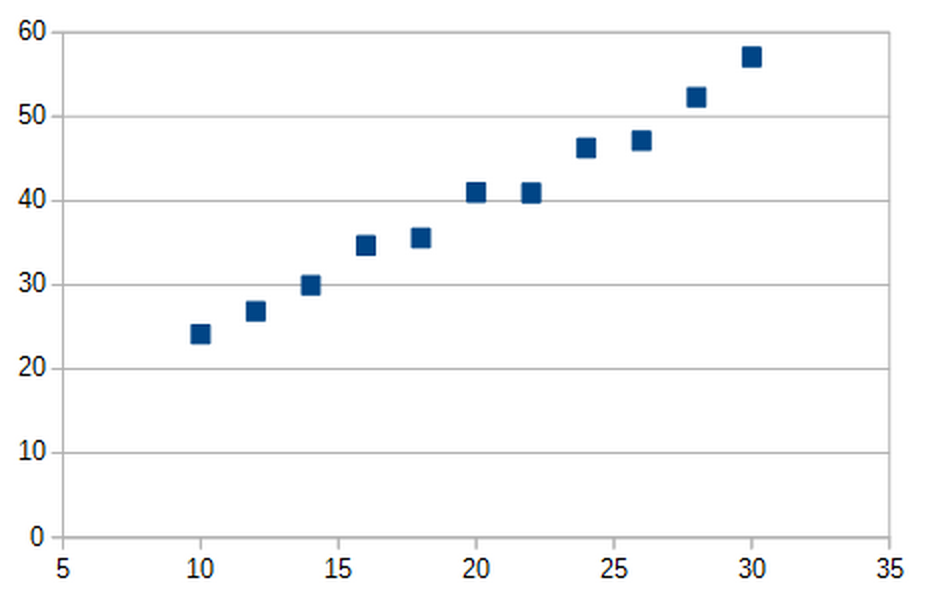
Well, that’s great. We now have a bunch of data. But what do these data points really mean? How should we interpret them, and what knowledge can we gain from them? Even though it may seem obvious, there’s actually infinitely many ways to interpret these data points, all of them radically different from each other. For example, you could draw a simple straight line which seems to fit the data pretty well.
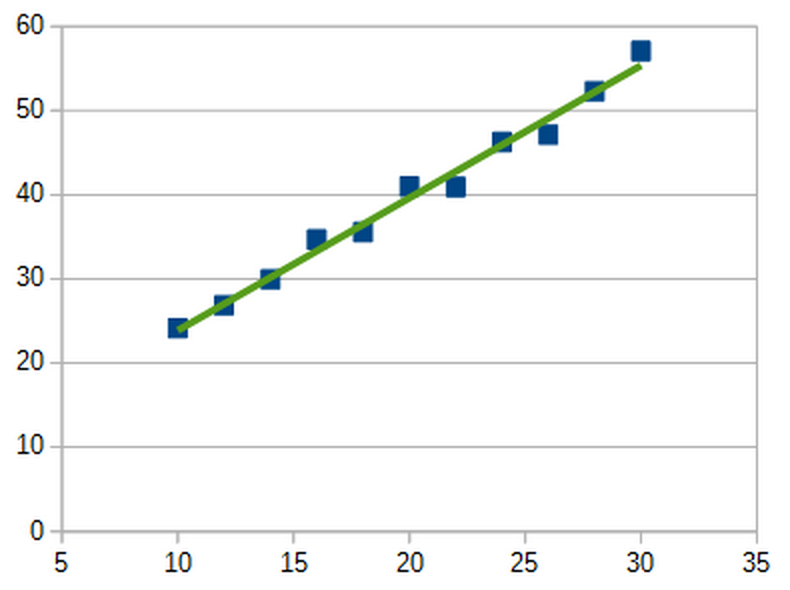
You could draw a very finely tuned curving function which fits the data even more closely.
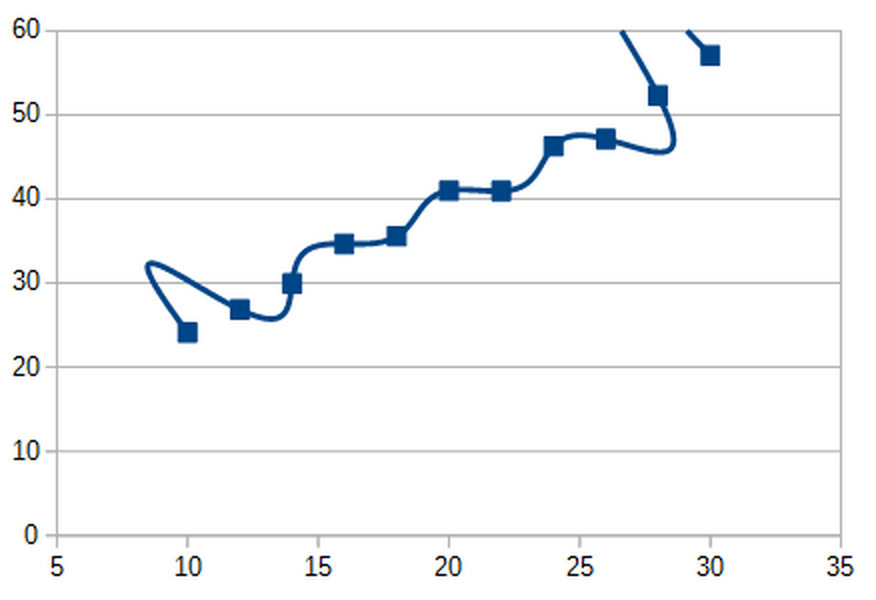
You could even draw crazy zig zag lines that fit the data points perfectly. All 3 options fit the data well, but lead to wildly different conclusions on how the world actually works. And there are thousands of other such options possible as well. How do we actually know which of these options to pick?
There’s actually an answer to this dilemma, and it forms the bedrock of all science. It’s a very simple principle known as Occam’s Razor, which sure enough, says that anytime you have a choice between 2 explanations, you should pick the one that is simpler. For those of us who are lazy, this seems like a godsend. The simpler option is much less work to understand & model, so that sure saves us a lot of time & effort!
But there’s also a more powerful factor at play. Not only is the simpler explanation the lazier option, it is also the more accurate one. If you have to choose between 2 explanations that equally match the data, the simpler one is the one that is most likely to be true! Hence why in science & math, there is so much importance placed on “beautiful” and “elegant” answers, as opposed to overly complicated ones. Albert Einstein said it best: “Everything should be as simple as it can be”.
And this is a lesson we can apply in our lives as well. When trying to understand something, always go for the simplest explanation that fits. If you went on a date with some guy, and he never called you back, did he meet with an accident? Was he kidnapped by the KGB and held in a gulag somewhere in Siberia? Or maybe he’s simply not interested in you? If 5 different people tell you that your new shirt looks very odd on you, are they jealous & trying to keep you down? Is there a massive behind-the-scenes conspiracy to fool you into throwing away a great shirt? Or maybe the shirt is actually not all that great? Always go with the simplest explanation.
Underfitting: Oversimplifying
Now suppose we go one step further. You look at all your data from before, remind yourself of Occam’s razor, and convince yourself that enzyme activity keeps going up with temperature. But then, as you run more and more experiment, something odd happens. At some point, the data seems to start diverging from your straight line.
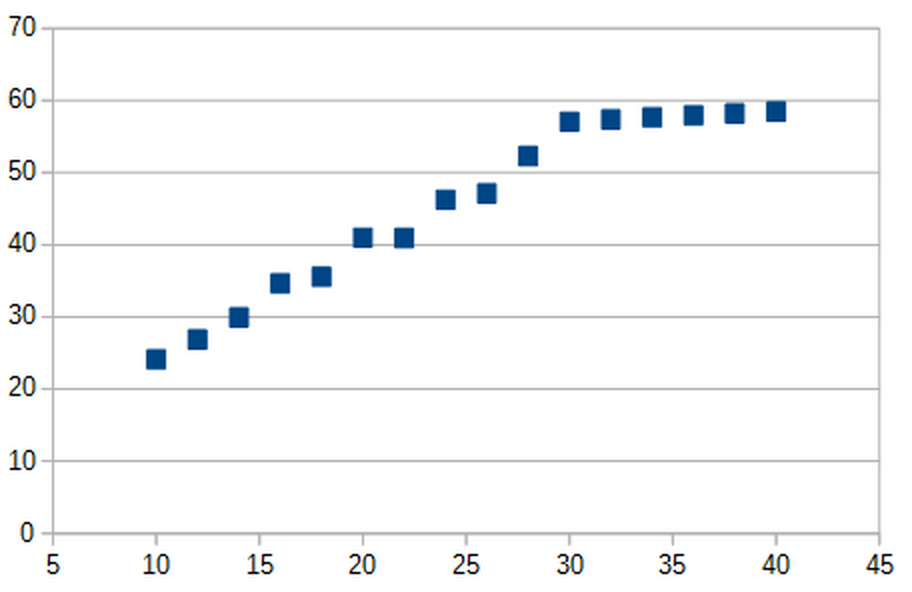
You try to redraw your line in a different way, but no matter how much you try, no straight line seems to match the data that you’re now seeing.
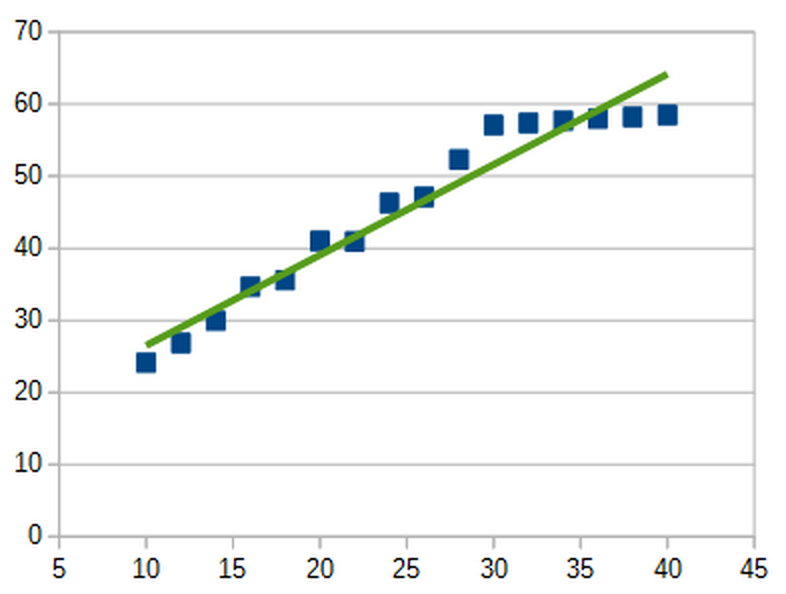
In Machine Learning, this is known as the “underfitting problem.” Ie, you’ve taken simplicity too far. You’re trying to model a very complex phenomenon with an explanation that is far too simple. In order to deal with this problem, you have to loosen up on your pursuit of simplicity, and search for a more complex explanation that better matches the data you’re seeing. You still don’t want to go overboard and pick an overly complicated explanation. But something that is slightly more complicated than your earlier straight-line hypothesis would now serve you best.
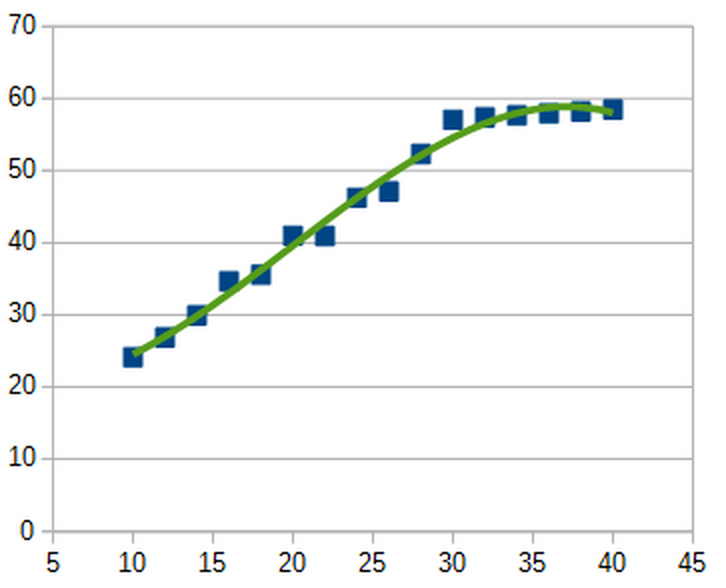
Once again, Albert Einstein said it best: “Everything should be as simple as it can be, but not simpler!” Pick the simplest explanation out there, but make sure it’s sophisticated enough to explain what you’re seeing.
This is something that will serve us well in our personal lives too. The best example of this, is something we all do subconsciously to some extent: Judging a book by its cover, generalizing, and stereotyping. We all do it to some extent. We constantly judge people & size them up based on such superficial factors like race, gender, religion, age, profession, height, weight, looks, and even the way we dress. The most dangerous thing about all these generalizations, is that they are always based on a little kernel of truth. That’s why people believe them, and that’s why they keep persisting.
And yet, despite this kernel of truth, the problem with generalizations is that they are overly simplistic, just like the straight line above. As human beings, we are all enormously complex and extremely varied. Anytime you try to lump together millions of people into one overly simplified bucket, you’re going to wind up with an extremely distorted vision of reality. And so it is too, with all knowledge. Always strive to find the simplest explanation possible, but no simpler.
Data is King
If this seems like quite the challenge, it certainly is! One the one hand, we always want to find the simplest explanation possible. But on the other hand, we don’t want it to be too simple either. How do we walk this fine line?
Let’s recall the experiments we were doing with enzymes earlier. First, we mistakenly believed that enzyme activity will always keep increasing with temperature. Then as we collected more data, we realized that this is only true up to a certain point, and that it eventually plateaus off. In fact, the truth is even worse; beyond a certain point, if you increase temperature even slightly, the curve plunges all the way down to zero. How can we avoid falling into such traps?
The answer to both puzzles is the same: Get more data. If the amount of data you have is too small, or if all your data falls into a very small range, it doesn’t matter how smart you are, or how great your data-processing capabilities are. You’ll keep making errors of both kinds, and continually misunderstand how the world really works. There’s even an Indian metaphor describing this, roughly translated as being a “Frog-in-a-well.” If you’re a frog living in a well for your entire life, then the entirety of your knowledge will be applicable only to the well that you’re in. You would think that the whole world consists of damp, dark conditions, with cylindrical walls & a small hole of light at the top.
In order to truly understand the world, you have to leave your well and start collecting much more data, from much more varied sources. Hence the common saying in Machine Learning that the amount of data you have, is even more important than how well you can process it. And so it is in our personal lives too. If you’ve spent your whole life in a small farming town in Ohio, then the entirety of your knowledge will be limited to life in small farming towns in the midwest. If you’ve spent your entire life in San Francisco, then the entirety of your knowledge will be limited to life in liberal American cities. If the entirety of your experiences with Mormons consist of the 2 people who came to your door to preach to you, you’d be much more prone to stereotyping them, than if you had 20 different Mormon friends.
The best way you can fight this problem? Get more data! Read more books. Watch more documentaries. Travel the country, travel the world. Make friends with people who are different from you. Read the NYTimes, and read WSJ. Watch MSNBC, and watch Fox News. Read the Bible, read the Quran, and read Richard Dawkins. Only by collecting as much data as possible, from as many varied sources as possible, can we best begin to make sense of how the world works.
Test Yourself
So you’ve now done all of the above. You’ve collected a wide array of data points. You’ve parsed all this data, and come up with a beautiful model for how the world works. A model that is as simple as possible, but also nicely fits all the data that you have. Is it now time to pop the champagne & bask in your supreme wisdom?
Not quite. Everyone in the world reaches this stage at some point in their life. In fact, this is the default stage that everyone is in for most of their life. They think they have enough data for their needs. They are confident that they interpretation of this data is a beautiful blend of simplicity and accuracy. After all, hindsight is 20/20. Everyone’s an expert after the fact.
But are you really an expert? Is your vision limited to great hindsight, or do you actually have great foresight as well? In order to know, you have to constantly test yourself. Ask yourself questions for which you don’t know the answer. Make a prediction based on your knowledge & beliefs. Then collect the data, and see if it matches your prediction. Anytime you come across a new piece of data, ask yourself whether it matches what you would have predicted.
If these answers don’t quite match your predictions, don’t just rationalize it or sweep it under a rug. Admit that your beliefs have been incorrect, or imprecise. Alter them to fit the new data, in a manner that still makes overall coherent sense. Be willing to throw your beliefs out entirely and start from scratch, if the situation calls for it. Pick explanations that are as simple as possible, while still being complex enough to explain what you’re seeing. And once you’re done with all that, gather even more data, and test yourself all over again. It’s a never ending loop, but with every lap that you take, you’ll find yourself a wiser person for it.
Life is the greatest epistemological problem of all. There are mountains of data that we’re constantly collecting everyday, and oceans more that is out there waiting to be collected. We arrive into this world not knowing anything, and using only these data points, we try to put them together in a way that makes this massive, immensely complex world, slightly more understandable.
This is exactly the same problem that Machine Learning scientists have been tackling for decades, in a much more structured format. They still have a long way to go, but their insights have been powerful enough to produce computer programs that can recognize human handwriting and self-drive cars. By learning from and applying these insights to our own lives, we too, can hope to make slightly better sense of this mysterious and magical world that we live in.
Related links:
The dangers of overfitting
How Data Scientists “keep it simple”
The overfitting-underfitting tradeoff

Dear OZ,
I enjoyed reading this. I have a background in physics and have watched with interest the development of some of these computer based and enhanced approaches to understanding the world.
Here’s a question for you: what counts as “data” in our lives? I think that something is only data when viewed within the framework of a formulated question. And how do we choose and formulate these questions? Which questions do we ask?
To me, this is the piece that is somewhat missing from your account of life. The questions are taken as given. Only then can everything be seen as data.
My two cents.
Regards,
Boaz
Reblogged this on Virgilio Leonardo Ruilova Castillo.